Getting distributed training jobs to run on huge clusters is hard! This is especially true when you start looking at more complex setups like distributed reinforcement learning. Debugging these kinds of jobs is frustrating, and the turnaround time for changes tends to be very slow.
Monarch is a distributed programming framework for PyTorch that makes the cluster programmable through a simple Python API. It exposes the supercomputer as a coherent, directly controllable system—bringing the experience of local development to large-scale training, as if your laptop had 1000s of GPUs attached. A complete training system can be defined in a single Python program. Core primitives are explicit and minimal, enabling higher-level capabilities—fault tolerance, orchestration, tooling integration—to be built as reusable libraries.
Monarch is optimized for agentic usage, providing consistent infrastructure abstractions and exposing telemetry via standard SQL-based APIs that agents already excel at using. Agents can do a lot of development tasks by just running on your dev machine, and Monarch is really good at turning your devmachine into a supercomputer, leveling-up those agents.
The project launched at the PyTorch conference in October 2025; you can read about it here: Introducing PyTorch Monarch. This blog covers how Monarch has evolved into an effective framework for agent-driven training development. It will also cover Monarch’s major improvements since October, including native Kubernetes support, RDMA improvements, distributed telemetry, and more.
Agentic Development in Monarch
By representing your supercomputing cluster through a coherent model of hosts, procs, and actors, and pairing it with “batteries included” infrastructure, Monarch gives your agent superpowers! It can directly manage and debug running code, rapidly sync dependencies and data, run new code, and provision additional hosts, procs, and actors in an efficient and consistent way regardless of where it is deployed.
Let’s quickly review some key features Monarch uses to empower agentic development:
- RDMA-Powered Remote File System – Distribute files from the client on a read-only mounted filesystem to every host in the job via RDMA. This lets you very rapidly sync code, dependencies, and containers while iterating on the machine learning ideas. Monarch’s RDMA filesystem in turn is built on Monarch RDMA buffers and PyFuse.
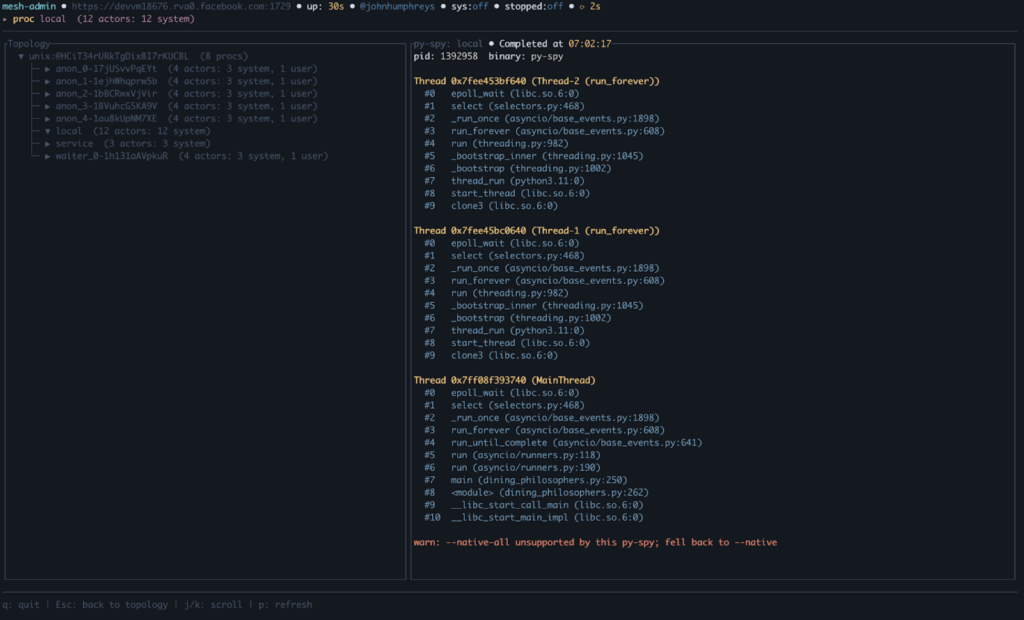
- Distributed SQL Telemetry – Use Monarch’s integrated lightweight distributed SQL engine to collect live state information, pyspy traces, and logs from all distributed processes/actors/etc. We used Monarch to directly run a DataFusion distributed SQL query engine *in situ*; each node in turn writes live state information into a set of tables that can then be queried directly and efficiently by an agent. This makes it very easy to explore the state of the system when debugging.
- Jobs API – Provision resources (hosts) once and run as many jobs as needed on them without paying the repeated allocation penalty. Monarch comes with support for Kubernetes and SLURM; other schedulers can be integrated by implementing a Monarch Job.
Collectively, these features enable agents to be efficient across some key phases of development; they can restart jobs fast, sync new code, dependencies, and data fast, and debug fast, all from a central point. In short, Monarch makes the distributed system feel local and provides a toolbox to reduce the iteration time when tackling problems.
What’s new in Monarch?
Let’s review what is new in Monarch since its launch at the PyTorch Conference in October 2025 (~6 months ago).
Kubernetes
Monarch now has first-class Kubernetes support.
- Monarch-kubernetes OSS repository – A dedicated repo (github.com/meta-pytorch/monarch-kubernetes) with a MonarchMesh Custom Resource Definition, a reference KubeBuilder operator, and a hello-world demo. The MonarchMesh label propagation also enables scheduling via Kueue.
- Just-in-time pod provisioning – Pods are allocated on demand rather than reserved upfront, improving cluster utilization.
- External gateway – Out-of-cluster clients can now connect to Monarch meshes running inside Kubernetes (landing in 0.5).
- Versioned and nightly Docker containers – Published to GHCR for reproducible deployments.
RDMA & Networking
Monarch has continued its investment in RDMA, adding support for multiple new backends and providing a higher-level API to make supporting and using them easier.
- AWS EFA RDMA support – Monarch’s RDMABuffer now supports Elastic Fabric Adapter (EFA) on AWS, extending high-performance networking beyond InfiniBand. Validated at 16 Gbps – 10x faster than TCP (14.5 GB in 7.6 seconds). Available in PyPI nightlies.
- AMD ROCm GPU support – GPU-direct RDMA and RCCL collective communication now work on AMD GPUs via ROCm with Mellanox interfaces.
- Unified RDMA API – A hardware-portable RDMA interface that works across InfiniBand (mlx5), AWS EFA, and ROCm, letting users write once and run on any fabric, or fall back to Monarch actor messaging when not available.
Observability & Telemetry
Monarch has leaned heavily into observability & telemetry, adding programmatic mechanisms to empower agentic development. There are also new native dashboards, Terminal UI (TUIs), and support for OSS standards commonly used by DevOps teams.
- Distributed SQL Telemetry – A client-accessible SQL endpoint, enabling easy analysis of the distributed system without 3rd party dependencies.
- Admin API & Terminal UI – A terminal-based interface for inspecting and managing live Monarch jobs, backed by a powerful API for accessing internals.
- OpenTelemetry integration – Native OTel support for metrics, logs, and visualization on Kubernetes, giving users full observability on any cluster. This is easily integrated with Prometheus, Loki, Grafana, and other common OSS tooling.
- Per-job OSS dashboard (Beta) – A built-in web dashboard for visualizing and debugging distributed jobs without external tooling.
Portability & Installation
Monarch is now significantly more compact and much faster to start, making it easier to use than ever.
- 100x smaller install, 8x faster startup – The pip wheel footprint was reduced by two orders of magnitude with dramatically faster cold-start times. libpython linking requirements were removed entirely.
- Torch dependency removed – As of v0.2, torchmonarch no longer pulls in torch as a pip dependency, simplifying installation and avoiding version conflicts.
- Native uv support – Monarch works out of the box with uv, the fast Python package manager. Three commands to get started: git clone, cd, uv run example.py. See the example repo.
- Consolidated PyPI packaging – All packages unified under a single torchmonarch name with PEP 440 pre-release versioning for nightlies: pip install –pre torchmonarch. ARM64 Linux builds are added as well to v0.4
Developer Experience
- Interactive SPMD – Improved support for interactive, notebook-style development with SPMD (Single Program, Multiple Data) jobs.
- RDMA File System – Fast, convenient file-sync across hosts.
Collaborations
We’d also like to take a moment to acknowledge some collaborators that have helped make Monarch better since its release.
- SkyPilot
- Run Monarch on any Kubernetes cluster with a single command – the SkyPilot integration lets users sky launch Monarch workloads on any K8s cluster or cloud without changing their Monarch code. Great for teams that need GPUs wherever they’re available.
- Multi-node distributed training with zero infra setup – SkyPilot handles node provisioning, networking, and gang scheduling so users can focus on their Monarch training logic. The integration uses Monarch’s JobTraits API to plug into SkyPilot as the job backend. No need to install separate operators on your k8s clusters.
- See https://github.com/meta-pytorch/monarch/tree/main/examples/skypilot for more.
- VERL
- VERL is a popular open-source framework for distributed RLHF post-training. In collaboration with ByteDance’s VeRL team, we developed a Monarch backend for VeRL’s single-controller architecture, implementing new resource pool abstractions built on Monarch’s Job API, colocated multi-role worker support, an RDMA-based transport layer that moves tensors out-of-band for VeRL’s DataProto exchange pattern, and a vLLM server integration that solves actor handle discovery without relying on a global actor registry. We validated that VeRL’s PPO and GRPO training loops can run on Monarch through this backend using VeRL’s hybrid-engine training mode, producing numerically identical results with no performance regression. One finding from this work: while VeRL’s single-controller interface is cleanly abstracted, Ray API usage surfaces throughout the broader codebase — making a non-invasive backend swap more involved than the interface alone suggests. This is a common pattern in frameworks built on Ray, and something the Monarch and VeRL communities can collaborate on over time.
- AMD
- Monarch expanded its compatibility and performance across leading hardware infrastructure adding AMD as a supported platform. Our partners at AMD validated Monarch on their ROCm platform, enabling seamless SLURM-based orchestration for MI300/325/355 clusters. This integration allows users to efficiently schedule, manage, and scale AI workloads across AMD GPUs, leveraging the familiar SLURM ecosystem widely used in HPC and AI research.
- Thanks to their effort, Monarch now supports RDMA (Remote Direct Memory Access) for fast GPU-to-GPU communication on AMD clusters equipped with Mellanox network interfaces. This hardware combination is available on major cloud providers like Azure and Oracle, enabling high-throughput, low-latency data transfers essential for distributed RL training and large-scale AI workloads.
Conclusion
Monarch is the API for your supercomputer; making distributed AI development feels like building a local app. The future of AI training demands speed and simplicity Monarch provides for both humans and agents. We encourage you to explore the latest features, join our growing OSS-first development community, and help shape the next chapter of distributed computing.
Acknowledgments
Thank you to the whole Monarch team for making this work possible. Also, a special thanks to our Top Contributors on GitHub!
- 🙏 Special thanks to our partners at Google Cloud and Runhouse for helping integrate monarch with kubernetes, and to our partners at SkyPilot and AMD for their contributions!
Ahmad Sharif, Allen Wang, Ali Sol, Amir Afzali, Carole-Jean Wu, Chris Gottbrath, Christian Puhrsch, Colin Taylor, Do Hyung (Dave) Kwon, Gayathri Aiyer, Hamid Shojanazeri, Jiyue Wang, Joe Spisak, John William Humphreys, Jun Li, Lucas Pasqualin, Marius Eriksen, Matthew Zhang, Matthias Reso, Peng Zhang, Riley Dulin, Rithesh Baradi, Robert Rusch, Sam Lurye, Samuel Hsia, Shayne Fletcher, Tao Lin, Thomas Wang, Victoria Dudin, Zachary DeVito
Facts Only
Monarch is a distributed programming framework for PyTorch that simplifies cluster management through a Python API.
It was launched at the PyTorch Conference in October 2025.
Monarch provides primitives for fault tolerance, orchestration, and tooling integration.
Key features include an RDMA-powered remote file system, distributed SQL telemetry, and a Jobs API for resource provisioning.
Since launch, Monarch has added native Kubernetes support, including a MonarchMesh Custom Resource Definition and just-in-time pod provisioning.
RDMA support has expanded to include AWS EFA and AMD ROCm, with a unified API for hardware portability.
Observability tools now include a distributed SQL endpoint, OpenTelemetry integration, and a built-in web dashboard.
Installation improvements include a 100x smaller pip wheel, 8x faster startup, and removal of PyTorch as a dependency.
Collaborations include SkyPilot for Kubernetes integration, VeRL for distributed RLHF training, and AMD for ROCm compatibility.
Monarch supports interactive SPMD development and fast file synchronization across hosts.
The project is open-source and emphasizes community-driven development.
Executive Summary
Monarch is a distributed programming framework for PyTorch designed to simplify large-scale AI training by making clusters feel like local development environments. It provides a Python API that abstracts complex distributed systems into manageable primitives, enabling faster iteration and debugging. Key features include RDMA-powered file synchronization, distributed SQL telemetry for real-time system monitoring, and a Jobs API for efficient resource provisioning. Since its launch at the PyTorch Conference in October 2025, Monarch has expanded with native Kubernetes support, improved RDMA backends (including AWS EFA and AMD ROCm), and enhanced observability tools like OpenTelemetry integration and built-in dashboards. Collaborations with projects like SkyPilot, VeRL, and AMD have further extended its capabilities, making it more portable and hardware-agnostic. The framework aims to bridge the gap between local development and supercomputing, empowering both human developers and AI agents to manage distributed training more efficiently.
The project emphasizes agentic development, where AI agents can directly interact with the cluster to manage jobs, sync dependencies, and debug issues. Recent updates have focused on reducing installation complexity, improving startup times, and removing dependencies like PyTorch to avoid version conflicts. Monarch’s approach to distributed computing is designed to reduce the friction traditionally associated with large-scale training, offering a unified interface that works across different hardware and scheduling systems. The framework’s evolution reflects a broader trend toward making high-performance computing more accessible and programmable, with a strong emphasis on open-source collaboration and community-driven development.
Full Take
Monarch presents itself as a revolutionary tool for distributed AI training, promising to democratize supercomputing by making clusters as accessible as local development environments. The strongest version of this narrative is compelling: by abstracting away the complexities of distributed systems, Monarch could significantly reduce the barrier to entry for large-scale AI research, enabling faster iteration and more efficient debugging. The framework’s focus on agentic development—where AI agents can autonomously manage and debug training jobs—aligns with the growing trend of AI-driven workflows. The collaborations with SkyPilot, VeRL, and AMD further bolster its credibility, demonstrating real-world applicability across different hardware and software ecosystems.
However, the narrative also raises questions about the trade-offs between abstraction and control. While Monarch’s high-level API simplifies development, it may obscure the underlying complexities of distributed systems, potentially limiting the depth of understanding for developers who rely on it. The emphasis on agentic development, while innovative, could also introduce new challenges in debugging and accountability, as AI agents make decisions that might be difficult to trace or override. Additionally, the framework’s rapid evolution—with major updates in just six months—suggests a dynamic but potentially unstable ecosystem, which could pose risks for long-term adoption.
The broader implication here is the tension between accessibility and expertise. As tools like Monarch lower the barrier to entry for distributed computing, they may also contribute to a skills gap where fewer developers understand the underlying systems. This could lead to a reliance on "black box" solutions, where the ability to troubleshoot or optimize at a deeper level is diminished. The framework’s success will likely depend on how well it balances ease of use with transparency and control.
**Bridge Questions:**
How might the abstraction provided by Monarch affect the long-term expertise of developers in distributed systems?
What are the potential risks of relying on AI agents for managing complex training jobs, particularly in terms of accountability and debugging?
How does Monarch’s rapid evolution impact its stability and adoption in production environments?
**Counterstrike Scan:**
If this narrative were part of a coordinated influence campaign, the playbook might involve exaggerating the ease of use while downplaying the complexities and risks of distributed systems. The actual content, however, appears to acknowledge these challenges and provides concrete examples of collaborations and improvements, suggesting a genuine effort to address real-world needs rather than a manipulative strategy.
**Patterns detected: none**
Sentinel — Human
The provided text is likely written by a human. It exhibits signs of erratic sentence structure, idiosyncratic emphasis, and no fabricated claims.