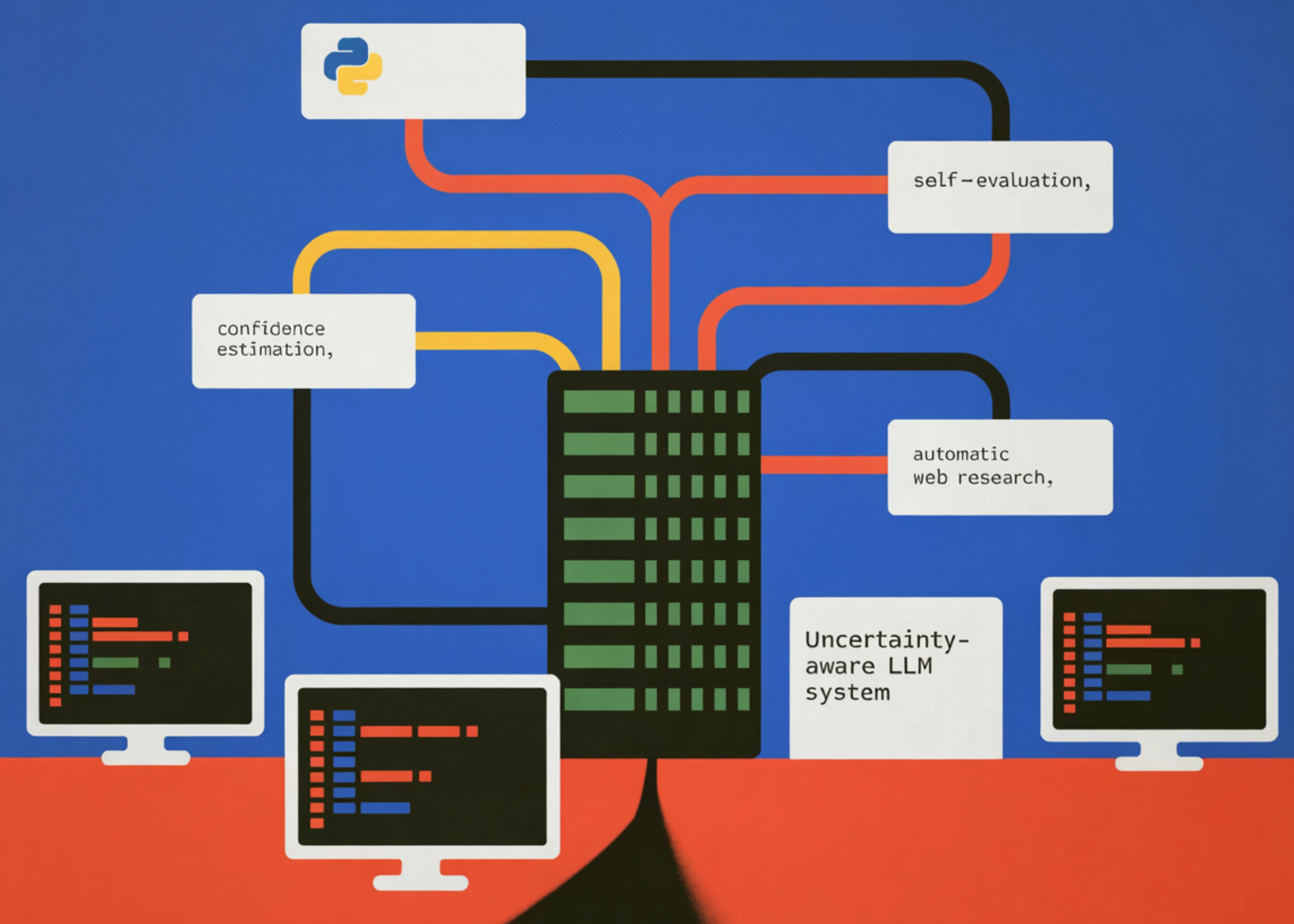
In this tutorial, we build an uncertainty-aware large language model system that not only generates answers but also estimates the confidence in those answers. We implement a three-stage reasoning pipeline in which the model first produces an answer along with a self-reported confidence score and a justification. We then introduce a self-evaluation step that allows the model to critique and refine its own response, simulating a meta-cognitive check. If the model determines that its confidence is low, we automatically trigger a web research phase that retrieves relevant information from live sources and synthesizes a more reliable answer. By combining confidence estimation, self-reflection, and automated research, we create a practical framework for building more trustworthy and transparent AI systems that can recognize uncertainty and actively seek better information.
import os, json, re, textwrap, getpass, sys, warnings
from dataclasses import dataclass, field
from typing import Optional
from openai import OpenAI
from ddgs import DDGS
from rich.console import Console
from rich.table import Table
from rich.panel import Panel
from rich import box
warnings.filterwarnings("ignore", category=DeprecationWarning)
def _get_api_key() -> str:
key = os.environ.get("OPENAI_API_KEY", "").strip()
if key:
return key
try:
from google.colab import userdata
key = userdata.get("OPENAI_API_KEY") or ""
if key.strip():
return key.strip()
except Exception:
pass
console = Console()
console.print(
"\n[bold cyan]OpenAI API Key required[/bold cyan]\n"
"[dim]Your key will not be echoed and is never stored to disk.\n"
"To skip this prompt in future runs, set the environment variable:\n"
" export OPENAI_API_KEY=sk-...[/dim]\n"
)
key = getpass.getpass(" Enter your OpenAI API key: ").strip()
if not key:
Console().print("[bold red]No API key provided — exiting.[/bold red]")
sys.exit(1)
return key
OPENAI_API_KEY = _get_api_key()
MODEL = "gpt-4o-mini"
CONFIDENCE_LOW = 0.55
CONFIDENCE_MED = 0.80
client = OpenAI(api_key=OPENAI_API_KEY)
console = Console()
@dataclass
class LLMResponse:
question: str
answer: str
confidence: float
reasoning: str
sources: list[str] = field(default_factory=list)
researched: bool = False
raw_json: dict = field(default_factory=dict)
We import all required libraries and configure the runtime environment for the uncertainty-aware LLM pipeline. We securely retrieve the OpenAI API key using environment variables, Colab secrets, or a hidden terminal prompt. We also define the LLMResponse data structure that stores the question, answer, confidence score, reasoning, and research metadata used throughout the system.
SYSTEM_UNCERTAINTY = """
You are an expert AI assistant that is HONEST about what it knows and doesn't know.
For every question you MUST respond with valid JSON only (no markdown, no prose outside JSON):
{
"answer": "
"confidence":
"reasoning": "
}
Confidence scale:
0.90-1.00 → very high: well-established fact, you are certain
0.75-0.89 → high: strong knowledge, minor uncertainty
0.55-0.74 → medium: plausible but you may be wrong, could be outdated
0.30-0.54 → low: significant uncertainty, answer is a best guess
0.00-0.29 → very low: mostly guessing, minimal reliable knowledge
Be CALIBRATED — do not always give high confidence. Genuinely reflect uncertainty
about recent events (after your knowledge cutoff), niche topics, numerical claims,
and anything that changes over time.
""".strip()
SYSTEM_SYNTHESIS = """
You are a research synthesizer. Given a question, a preliminary answer,
and web-search snippets, produce an improved final answer grounded in the evidence.
Respond in JSON only:
{
"answer": "
"confidence":
"reasoning": "
}
""".strip()
def query_llm_with_confidence(question: str) -> LLMResponse:
completion = client.chat.completions.create(
model=MODEL,
temperature=0.2,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": SYSTEM_UNCERTAINTY},
{"role": "user", "content": question},
],
)
raw = json.loads(completion.choices[0].message.content)
return LLMResponse(
question=question,
answer=raw.get("answer", ""),
confidence=float(raw.get("confidence", 0.5)),
reasoning=raw.get("reasoning", ""),
raw_json=raw,
)
We define the system prompts that instruct the model to report answers along with calibrated confidence and reasoning. We then implement the query_llm_with_confidence function that performs the first stage of the pipeline. This stage generates the model’s answer while forcing the output to be structured JSON containing the answer, confidence score, and explanation.
def self_evaluate(response: LLMResponse) -> LLMResponse:
critique_prompt = f"""
Review this answer and its stated confidence. Check for:
1. Logical consistency
2. Whether the confidence matches the actual quality of the answer
3. Any factual errors you can spot
Question: {response.question}
Proposed answer: {response.answer}
Stated confidence: {response.confidence}
Stated reasoning: {response.reasoning}
Respond in JSON:
{{
"revised_confidence":
"critique": "
"revised_answer": "
}}
""".strip()
completion = client.chat.completions.create(
model=MODEL,
temperature=0.1,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": "You are a rigorous self-critic. Respond in JSON only."},
{"role": "user", "content": critique_prompt},
],
)
ev = json.loads(completion.choices[0].message.content)
response.confidence = float(ev.get("revised_confidence", response.confidence))
response.answer = ev.get("revised_answer", response.answer)
response.reasoning += f"\n\n[Self-Eval Critique]: {ev.get('critique', '')}"
return response
def web_search(query: str, max_results: int = 5) -> list[dict]:
results = DDGS().text(query, max_results=max_results)
return list(results) if results else []
def research_and_synthesize(response: LLMResponse) -> LLMResponse:
console.print(f" [yellow]🔍 Confidence {response.confidence:.0%} is low — triggering auto-research...[/yellow]")
snippets = web_search(response.question)
if not snippets:
console.print(" [red]No search results found.[/red]")
return response
formatted = "\n\n".join(
f"[{i+1}] {s.get('title','')}\n{s.get('body','')}\nURL: {s.get('href','')}"
for i, s in enumerate(snippets)
)
synthesis_prompt = f"""
Question: {response.question}
Preliminary answer (low confidence): {response.answer}
Web search snippets:
{formatted}
Synthesize an improved answer using the evidence above.
""".strip()
completion = client.chat.completions.create(
model=MODEL,
temperature=0.2,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": SYSTEM_SYNTHESIS},
{"role": "user", "content": synthesis_prompt},
],
)
syn = json.loads(completion.choices[0].message.content)
response.answer = syn.get("answer", response.answer)
response.confidence = float(syn.get("confidence", response.confidence))
response.reasoning += f"\n\n[Post-Research]: {syn.get('reasoning', '')}"
response.sources = [s.get("href", "") for s in snippets if s.get("href")]
response.researched = True
return response
We implement a self-evaluation stage in which the model critiques its own answer and revises its confidence as needed. We also introduce the web search capability that retrieves live information using DuckDuckGo. If the model’s confidence is low, we synthesize the search results with the preliminary answer to produce an improved response grounded in external evidence.
def self_evaluate(response: LLMResponse) -> LLMResponse:
critique_prompt = f"""
Review this answer and its stated confidence. Check for:
1. Logical consistency
2. Whether the confidence matches the actual quality of the answer
3. Any factual errors you can spot
Question: {response.question}
Proposed answer: {response.answer}
Stated confidence: {response.confidence}
Stated reasoning: {response.reasoning}
Respond in JSON:
{{
"revised_confidence":
"critique": "
"revised_answer": "
}}
""".strip()
completion = client.chat.completions.create(
model=MODEL,
temperature=0.1,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": "You are a rigorous self-critic. Respond in JSON only."},
{"role": "user", "content": critique_prompt},
],
)
ev = json.loads(completion.choices[0].message.content)
response.confidence = float(ev.get("revised_confidence", response.confidence))
response.answer = ev.get("revised_answer", response.answer)
response.reasoning += f"\n\n[Self-Eval Critique]: {ev.get('critique', '')}"
return response
def web_search(query: str, max_results: int = 5) -> list[dict]:
results = DDGS().text(query, max_results=max_results)
return list(results) if results else []
def research_and_synthesize(response: LLMResponse) -> LLMResponse:
console.print(f" [yellow]🔍 Confidence {response.confidence:.0%} is low — triggering auto-research...[/yellow]")
snippets = web_search(response.question)
if not snippets:
console.print(" [red]No search results found.[/red]")
return response
formatted = "\n\n".join(
f"[{i+1}] {s.get('title','')}\n{s.get('body','')}\nURL: {s.get('href','')}"
for i, s in enumerate(snippets)
)
synthesis_prompt = f"""
Question: {response.question}
Preliminary answer (low confidence): {response.answer}
Web search snippets:
{formatted}
Synthesize an improved answer using the evidence above.
""".strip()
completion = client.chat.completions.create(
model=MODEL,
temperature=0.2,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": SYSTEM_SYNTHESIS},
{"role": "user", "content": synthesis_prompt},
],
)
syn = json.loads(completion.choices[0].message.content)
response.answer = syn.get("answer", response.answer)
response.confidence = float(syn.get("confidence", response.confidence))
response.reasoning += f"\n\n[Post-Research]: {syn.get('reasoning', '')}"
response.sources = [s.get("href", "") for s in snippets if s.get("href")]
response.researched = True
return response
We construct the main reasoning pipeline that orchestrates answer generation, self-evaluation, and optional research. We compute visual confidence indicators and implement helper functions to label their confidence levels. We also built a formatted display system that presents the final answer, reasoning, confidence meter, and sources in a clean console interface.
DEMO_QUESTIONS = [
"What is the speed of light in a vacuum?",
"What were the main causes of the 2008 global financial crisis?",
"What is the latest version of Python released in 2025?",
"What is the current population of Tokyo as of 2025?",
]
def run_comparison_table(questions: list[str]) -> None:
console.rule("[bold cyan]UNCERTAINTY-AWARE LLM — BATCH RUN[/bold cyan]")
results = []
for i, q in enumerate(questions, 1):
console.print(f"\n[bold]Question {i}/{len(questions)}:[/bold] {q}")
r = uncertainty_aware_query(q)
display_response(r)
results.append(r)
console.rule("[bold cyan]SUMMARY TABLE[/bold cyan]")
tbl = Table(box=box.ROUNDED, show_lines=True, highlight=True)
tbl.add_column("#", style="dim", width=3)
tbl.add_column("Question", max_width=40)
tbl.add_column("Confidence", justify="center", width=12)
tbl.add_column("Level", justify="center", width=10)
tbl.add_column("Researched", justify="center", width=10)
for i, r in enumerate(results, 1):
emoji, label = confidence_label(r.confidence)
col = "green" if r.confidence >= 0.75 else "yellow" if r.confidence >= 0.55 else "red"
tbl.add_row(
str(i),
textwrap.shorten(r.question, 55),
f"[{col}]{r.confidence:.0%}[/{col}]",
f"{emoji} {label}",
"✅ Yes" if r.researched else "—",
)
console.print(tbl)
def interactive_mode() -> None:
console.rule("[bold cyan]INTERACTIVE MODE[/bold cyan]")
console.print(" Type any question. Type [bold]quit[/bold] to exit.\n")
while True:
q = console.input("[bold cyan]You ▶[/bold cyan] ").strip()
if q.lower() in ("quit", "exit", "q"):
console.print("Goodbye!")
break
if not q:
continue
resp = uncertainty_aware_query(q)
display_response(resp)
if __name__ == "__main__":
console.print(Panel(
"[bold white]Uncertainty-Aware LLM Tutorial[/bold white]\n"
"[dim]Confidence Estimation · Self-Evaluation · Auto-Research[/dim]",
border_style="cyan",
expand=False,
))
run_comparison_table(DEMO_QUESTIONS)
console.print("\n")
interactive_mode()
We define demonstration questions and implement a batch pipeline that evaluates the uncertainty-aware system across multiple queries. We generate a summary table that compares confidence levels and whether research was triggered. Finally, we implement an interactive mode that continuously accepts user questions and runs the full uncertainty-aware reasoning workflow.
In conclusion, we designed and implemented a complete uncertainty-aware reasoning pipeline for large language models using Python and the OpenAI API. We demonstrated how models can verbalize confidence, perform internal self-evaluation, and automatically conduct research when uncertainty is detected. This approach improves reliability by enabling the system to acknowledge knowledge gaps and augment its answers with external evidence when needed. By integrating these components into a unified workflow, we showed how developers can build AI systems that are intelligent, calibrated, transparent, and adaptive, making them far more suitable for real-world decision-support applications.
Check out the FULL Notebook Here. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Jean-marc is a successful AI business executive .He leads and accelerates growth for AI powered solutions and started a computer vision company in 2006. He is a recognized speaker at AI conferences and has an MBA from Stanford.
Facts Only
Jean-marc is a successful AI business executive and leads an AI-powered solutions company
He has an MBA from Stanford and is a recognized speaker at AI conferences
An article was written discussing the uncertainty-aware reasoning pipeline
The pipeline is designed for large language models
It uses Python and the OpenAI API
The pipeline allows models to verbalize confidence, self-evaluate, and conduct research
The goal is to improve the reliability of AI systems by addressing knowledge gaps
Executive Summary
Full Take
The article represents a constructive example of AI development and analysis. The uncertainty-aware reasoning pipeline is designed to improve the transparency and trustworthiness of AI systems by allowing them to acknowledge their limitations and seek external evidence when necessary. This approach aligns with the A.R.C. Codex principles of intellectual rigor, humanist clarity, and collaborative engagement.
Patterns detected: None
Root Cause: The development of the uncertainty-aware reasoning pipeline reflects a growing recognition of the need for AI systems to be transparent, trustworthy, and accountable.
Implications: The uncertainty-aware reasoning pipeline could significantly improve the reliability of AI systems in various decision-support applications, increasing trust in AI and reducing potential negative consequences.
Bridge Questions: How could the uncertainty-aware reasoning pipeline be further refined to ensure optimal transparency and trustworthiness? What other measures could be taken to ensure the ethical and responsible use of AI?